

本年清楚又是英伟达这家33岁公司又一个要津时刻,东谈主们像期待数码家具一样期待它的芯片更新,对超预期的财报甚而齐提不起趣味,眼看有些江郎才尽的时刻,黄仁勋又带来了新的故事。
3月16日,在2026年英伟达GTC大会上,黄仁勋作念了万众期待的主旨演讲。东谈主们看待英伟达,热心和惦念的齐是它的增长。而本年GTC,一个花200亿好意思金收购来的Groq,一个短暂就转变了一切并看起来处理了“诈骗普及问题”的OpenClaw,成了增长故事里的完全主角。
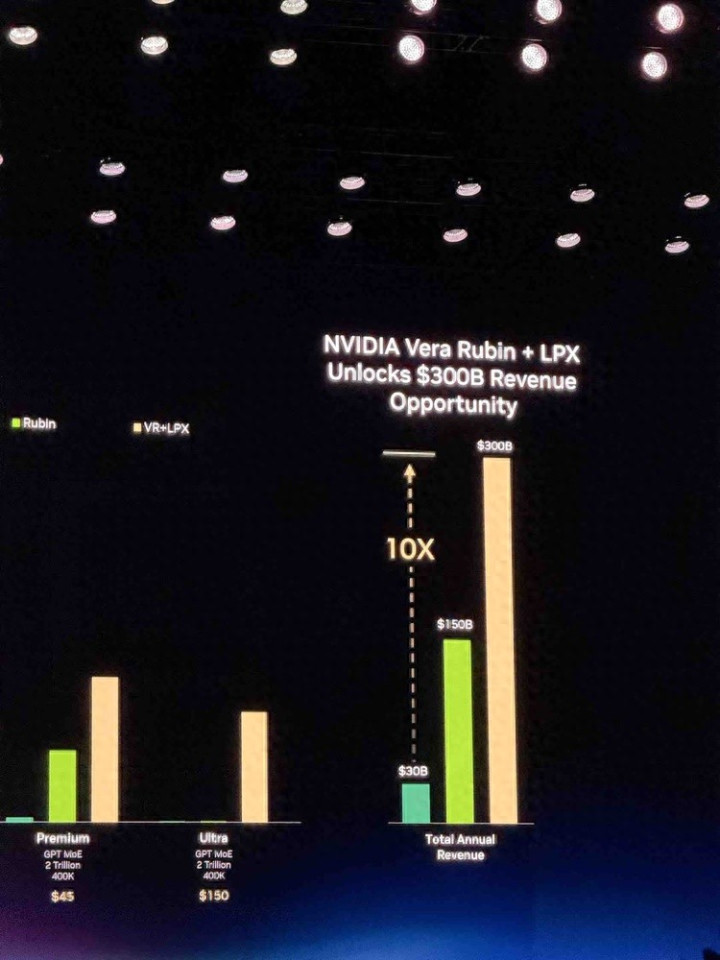
Groq的新芯片融入英伟达体系后,英伟达声称会给它的客户们解锁一个3000亿好意思金的增量市集;
同期英伟达也会把Groq更真切融入下一代芯片架构Feynman 里;
而在他完全不会迟到的“小龙虾”狂热里,黄仁勋要让英伟达造成OpenClaw们的底层,再次献艺一出CUDA相同的戏码。
尽管比拟GTC最明后的那些发布,本年的整个发布的大多期间显得有点乏善可陈,但这些一经弥漫让黄仁勋信心满满,他暗意:
2025年到2027年,英伟达的芯片生意将会连续高涨,涨到1万亿好意思金。
Vera Rubin + Groq,七颗芯片合体
黄仁勋展示了他描写为全新的AI基础才略层的全貌。
他不再举着一颗芯片说“this is our new GPU”了。他把整个Vera Rubin机架搬上了舞台,说这一次英伟达想的是整套系统,从芯片到软件到互连,端到端垂直整合,动作一台超等揣度机来优化。

上一代Blackwell Ultra一经收场了对比Hopper 50倍的微辞后果进步,而Vera Rubin + Groq在此基础上又把前沿推到了新的区间,这套系统由七颗芯片构成。中枢Rubin GPU继承台积电3nm工艺,双芯片封装,336B晶体管,配备288GB HBM4内存和22TB/s带宽,NVFP4推感性能达到50 PFLOPs,比上一代Blackwell进步5倍,历练性能35 PFLOPs,进步3.5倍。配套的Vera CPU是88审定制Arm架构(代号Olympus),176线程,全球首款在数据中心继承LPDDR5X的CPU,成心为Agent推理场景下的高单线程性能和数据处理作念了优化。黄仁勋说这颗CPU孤独卖“服气会成为数十亿好意思元的业务”。
但今晚果然的新闻是第七颗芯片,Groq 3 LPU。旧年圣诞夜英伟达花200亿好意思元拿下Groq的时刻授权和中枢团队,今天是初度家具落地,而且一经在量产。

为什么需要Groq?黄仁勋在台上讲得很了了,GPU擅长高微辞的并行揣度,作念prefill和attention很强,但在超高速token生成这个区间会力不从心。他的原话是NVL72在卓越400 tokens/s/user的区间“runs out of steam”(跑不动了)。而Groq的LPU是一种完全不同的处理器,细则性数据流架构,芯片上全是SRAM,莫得运转时动态转机,编译器在编译阶段就把每个时钟周期的揣度和数据搬运全部排好了。这种架构自然符合低延迟的decode和token生成。
问题在于SRAM虽快但容量极小。单颗Groq 3 LPU唯独500MB SRAM,而Rubin GPU是288GB HBM4,差了500多倍,根柢存不下万亿参数的模子。英伟达的解法是用一套叫Dynamo的软件把推理流程拆成两半,Rubin负责prefill和attention,处理高下文需要大批算力和大容量内存;Groq负责feed-forward部分的decode和token生成,需要极低延迟和极高带宽。两者通过以太网紧耦合,延迟减半。
黄仁勋管这个叫disaggregated inference(解耦推理),况且总结说高微辞和低延迟本体上enemies of each other(互相矛盾),而Groq便是处理这个矛盾的那一半拼图。

舞台上的那张对比图视觉冲击很强。
左边一颗Rubin GPU,288GB HBM4、22TB/s带宽、50 PFLOPs。
右边一排8颗Groq 3 LPU构成的阵列,4GB SRAM、1,200TB/s SRAM带宽(Rubin的55倍)、9.6 PFLOPs。
两种顶点的处理器,斡旋成一个推理系统。Groq 3 LPX整机把256颗LPU装进一个机架,提供128GB SRAM、40PB/s带宽、315 PFLOPS推理算力和640TB/s互连带宽。

整套NVL72系统100%液冷,用45度开水冷却,把蓝本花在空调上的能耗省回归给揣度用。安设期间从两天压缩到两小时。第六代NVLink提供3.6TB/s全互连带宽。首款CPO(共封装光学)交换机Spectrum X一经量产。
咫尺,微软Azure一经跑起了第一套Vera Rubin机架,Satya Nadella在演讲期间径直发音讯证据。
黄仁勋还给了一个极其直不雅的对比,祛除个1GW数据中心,两年内token生成速率从2200万进步到7亿,350倍。他说这便是极致协同筹谋的力量。
1万亿GPU,和新的营业模式可能
在演讲里,黄仁勋再次给出数据的率领。
旧年GTC他给出的对于英伟达家具的需求估算是5000亿好意思元(隐敝Blackwell和Rubin到2026年),而本年径直翻倍,他说咫尺看到的是:
到2027年至少1万亿好意思元。
驱能源是他反复提到的“推理拐点”,从ChatGPT到o1再到Claude Code,AI从能聊天造成能推理再造成颖慧活,每一步跨越齐让单次推理需要的算力暴增,而使用量也在同步升空。黄仁勋说Claude Code是第一个agentic model,英伟达100%的软件工程师齐在用。

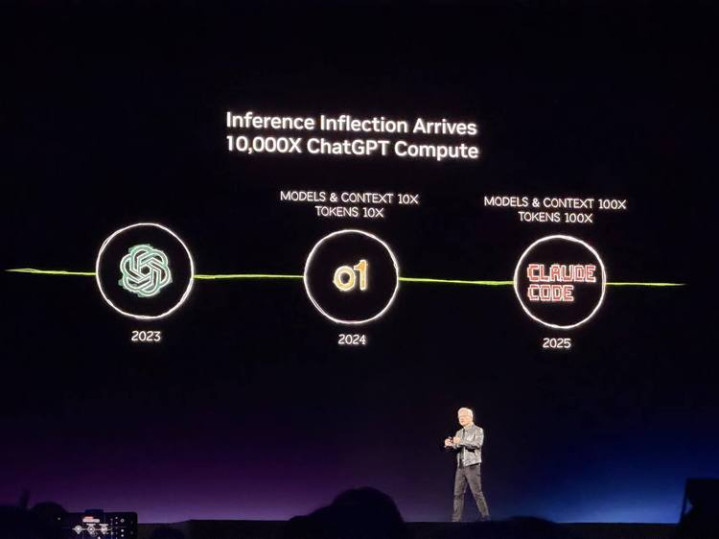
然后他用一张图把这个宏不雅判断翻译成了具体的营业逻辑。
整场演讲最值得反复看的便是这张,标题叫inference Performance and Efficiency Drive Company Results。
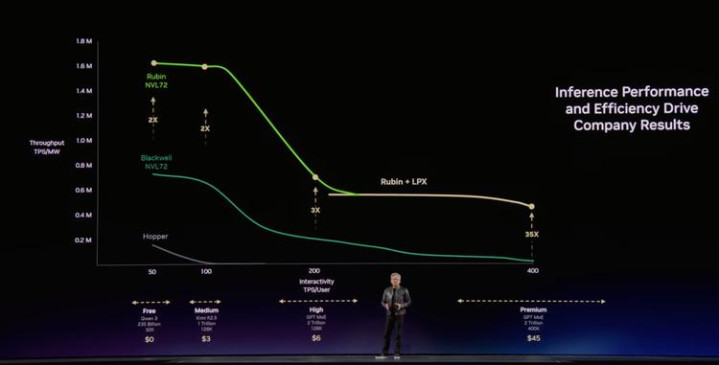
纵轴是微辞量(TPS/MW,每兆瓦每秒生成的token数),横轴是交互速率(TPS/User,每用户每秒拿到的token数)。横轴越往右意味着AI越“智谋”,模子更大、高下文更长、想考链更深,但微辞量会下跌,因为资源被单个用户的推理任务占用了更多。高微辞和低延迟本体上矛盾。
黄仁勋在横轴上切了五档订价。Free层用Qwen 3(235B参数,32K高下文,免费),Medium层用Kimi K2.5(1T参数,128K高下文,3好意思元/百万token),High层用GPT MoE(2T参数,128K,米兰体育6好意思元),Premium层相同是GPT MoE但高下文窗口拉到400K、价钱到45好意思元,Ultra层150好意思元。
然后他把四代硬件的弧线叠上去。Hopper只可隐敝Free和Medium层,在高交互区间弧线贴着底部。Blackwell大幅上移,让Premium层变得经济可行。Vera Rubin再上一档。加上Groq LPX之后,弧线在400+ TPS/User的高交互区间向右蔓延出去,对比Hopper进步35倍,让一个咫尺还不存在的Ultra层(150好意思元/百万token)成为可能。
动作一个“首席销售”,在第二张图,黄仁勋径直把这个逻辑翻译成了营收数字。
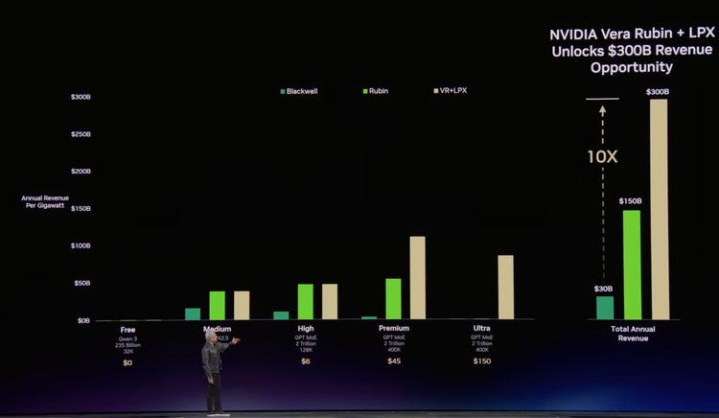
假定一个1GW数据中心按25%算力分拨给每个层级,每GW年营收Blackwell能作念300亿好意思元,Rubin作念1500亿(5倍),加上Groq LPX作念3000亿(10倍)。
两张图合在通盘看,叙事逻辑很澄莹:第一张为了告诉环球,Rubin让Premium推理($45/M tokens)变得赢利,而第二张则发挥了,Rubin + LPX不错让一个尚不存在的Ultra推理市集($150/M tokens)成为可能。
黄仁勋借此界说了一套token订价蹊径,并在这最进攻的大会上,径直告诉统共客户,这内部每一层的经济可行性齐径直绑定在英伟达的硬件代际升级上。
换句话说,莫得我的芯片,你到不了下一个价钱层级,你的营业模子跑欠亨。有了我,营业模子的新可能就出现了。
“数据中心是坐褥token的工场;推理是使命负载,token是新商品,算力等于营收;将来每个CEO齐要盯着我方token工场的着力看。”
他连续倾销英伟达:“用得越多省钱阅多。咱们是惟逐一个在每一个模子里齐在被使用的家具,这让咱们成为最强又最低廉的。英伟达的系统是全球领域内你可取得的本钱最低的AI基础才略。 ”
黄仁勋甚而径直给了不同客户部署决策:如果使命负载主如果高微辞的批量推理,100%配Vera Rubin就够了。如果有大批编程、高价值及时推理和Agent交互需求,拿25%数据中心配Groq LPX,其余75%纯Rubin。
AG百家乐APP官方网站Feynman剧透,2028年全部换代
在Rubin先容完后,Feynman的剧透来了。
英伟达给我方路线图节律锁死,每年一代新架构。现时Blackwell,2026下半年Vera Rubin,2027年Rubin Ultra搭配全新Kyber机架(揣度节点改为垂直插入,前置揣度后置互连,接济144颗GPU),2028年Feynman。
Feynman是黄仁勋今晚的one more thing式剧透,七个组件全部换代。全新GPU(此前传闻台积电A16 1.6nm),LP40 LPU(黄仁勋说是big step up,Groq团队加入英伟达后共同筹谋,初度在LPU中加入NVFP4揣度技艺),Rosa CPU(全名Rosalind,请安发现DNA结构的Rosalind Franklin),BlueField 5 DPU,ConnectX-10 SuperNIC,NVLink 8。Kyber机架同期接济铜缆和CPO光学互连。
对于铜缆如故光互连的行业争论,黄仁勋一句话闭幕,铜的要作念,光的也要作念,CPO也要作念,每一种齐需要更多的产能。
中间他还趁便提了Vera Rubin Space-1,要把揣度模块奉上天外作念数据中心。天外莫得传导和对流唯独辐照,散热是个问题,但英伟达一经在作念了。
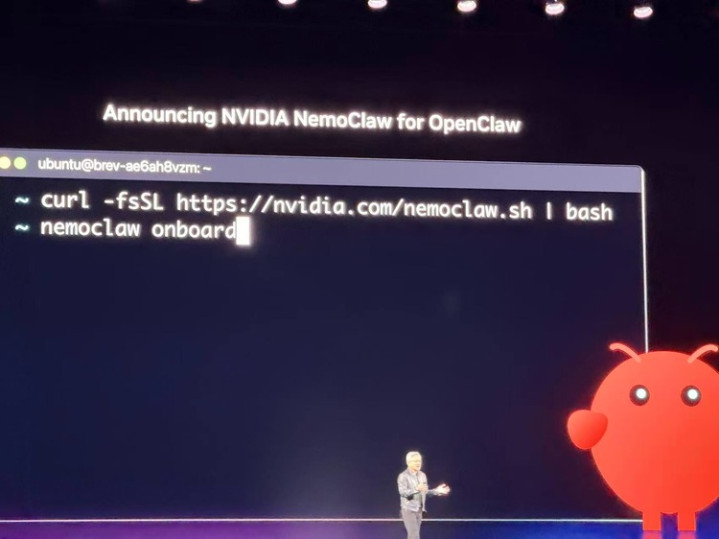
为龙虾作念“CUDA”,NemoClaw界说Agent时期的操作系统
对于最近纵脱的龙虾热,黄仁勋称Agent是一个全新的揣度平台,并径直把OpenClaw的定位拔到了和Windows、Linux、Kubernetes祛除级别。
他用操作系统的语法拆解了OpenClaw的本体,照顾资源、转机任务、调用器具、相接大模子、多模态IO、派生子Agent。OpenClaw几周内超越Linux 30年的GitHub Star数,是东谈主类历史上增长最快的开源格局。黄仁勋觉得它的意旨等同于HTML之于互联网、Kubernetes之于出动云,每家公司齐需要一个OpenClaw政策。
然后话锋一行,讲了企业场景的致命问题。Agent在公司内网能拜访敏锐信息、能实施代码、能对外通讯。黄仁勋让全场默念了一遍这三条,然后说,这清楚不成被允许。
NemoClaw便是英伟达的解法,但它不是别辟门户,而是给OpenClaw套上一层企业安全壳。中枢组件叫OpenShell,一经集成进OpenClaw,包含策略引擎接口(对接企业已有的安全合规系统)、收罗护栏(放纵Agent收罗拜访规模)和阴私路由(谨慎敏锐数据传奇)。开源,Apache 2.0合同,深度整合NeMo框架、Nemotron模子和NIM推理微办事。
这里的类比联系是,NemoClaw之于OpenClaw生态,就像CUDA之于GPU生态。
CUDA让GPU从游戏显卡造成了通用揣度平台,NemoClaw要让龙虾从个东谈主玩物造成企业基础才略。OpenClaw提供了Agent的操作系统,NemoClaw提供了在这个操作系统上安全运转企业诈骗的开拓平台和器具链。
黄仁勋的行业判断是,将来每家SaaS公司齐会造成GaaS(Generative-as-a-Service)公司,企业IT从2万亿好意思元的器具产业升级为多万亿好意思元的Agent产业。他甚而瞻望将来每个工程师入职时齐会拿到一份年度token预算,基本工资以外再加一半用于购买token,让个东谈主坐褥力放大10倍。“你的offer带几许token”会成为硅谷新的有计划筹码。

勾搭Agent生态,英伟达同期晓谕了Nemotron Coalition(开源模子定约)。六大模子眷属全部达到前沿水平,Nemotron(说话推理,OpenClaw评测前三)、Cosmos(物理AI寰球模子)、Alpamayo(自动驾驶,堪称首个会想考推理的自动驾驶AI)、GR00T(通用机器东谈主)、BioNeMo(生升天学)、Earth 2(天气场面)。Nemotron 3 Ultra定位为寰球最佳的基础模子,供列国作念主权AI定制。定约首批成员包括Black Forest Labs、Cursor、LangChain(10亿+下载量)、Mistral、Perplexity、Thinking Machines(Mira Murati创办)等。
英伟达的增长故事不成停。这一次一个可能成为比年英伟达最进攻的收购的Groq,和一个短暂出现的场面级全民狂热的OpenClaw让这个故事得以连续,黄仁勋也收拢了这些被他描写为“必须收拢的期间窗口”,把大批资源赌在了上头米兰体育官网,剩下的,就靠诸君通盘纵脱烧token了。
 备案号:
备案号: